Your feedback is highly appreciated
Implementing and standardizing Machine Learning practice on Cloud is every organization’s priority.
As you know, in Machine Learning there are two protagonists. One is a Data Engineer and the other one is a Data Scientist.
And whenever there are two or more protagonists, there is always a communication cost.
For example, when you ask data scientist, you will hear. I am a Data Scientist and my problem is:
- I end up in spending most of my time on data preparation.
- There is so much data inconsistency between training data & serving data
And now when you ask Data engineer, she will say. I am a Data Engineer and my problem is:
- I get so many Ad hoc requests from data scientists on data transformation & data readiness.
- It’s a challenge to identify repeatable implementations since everyone has their own flavor of data transformation.
It’s all about reducing communication costs between data engineers & data scientists. And that’s where the third protagonist enters, a DevOps engineer or the man behind the curtain.
So, in order to reduce communication cost between data engineers and data scientists, DevOps Engineers need to build or enable a Machine learning practice that empowers both data engineers as well as data scientists. And most importantly clearly defines & appreciates separation of duties.
The Target for data engineers to spend 70-75% on data prep and 25-30% on Feature extraction in collaboration with data scientists whereas for data scientists maximum focus & energy on Model optimization.
How to do it ? We should be asking these three questions to ourselves:
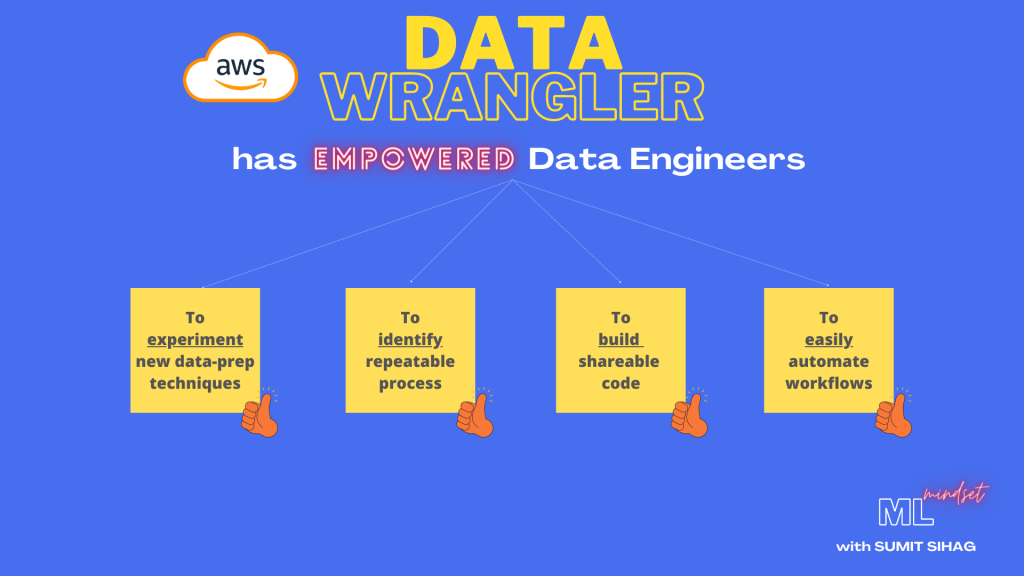
Are we embracing the Experimental Process ?
Basically are we spending enough time in implementing new data prep techniques or still relying on old processes.
Are we identifying repeatable implementations ?
Basically implementations that have been put in place in different ways & flavors by different individuals over the time. These repeatable implementations must be extracted, abstracted and then standardized.
Are we enabling shareable code process ?
Basically influencing and empowering data engineers to build shareable code so that data prep (or transformation) logic can be standardized and hosted as functions for others to consume.
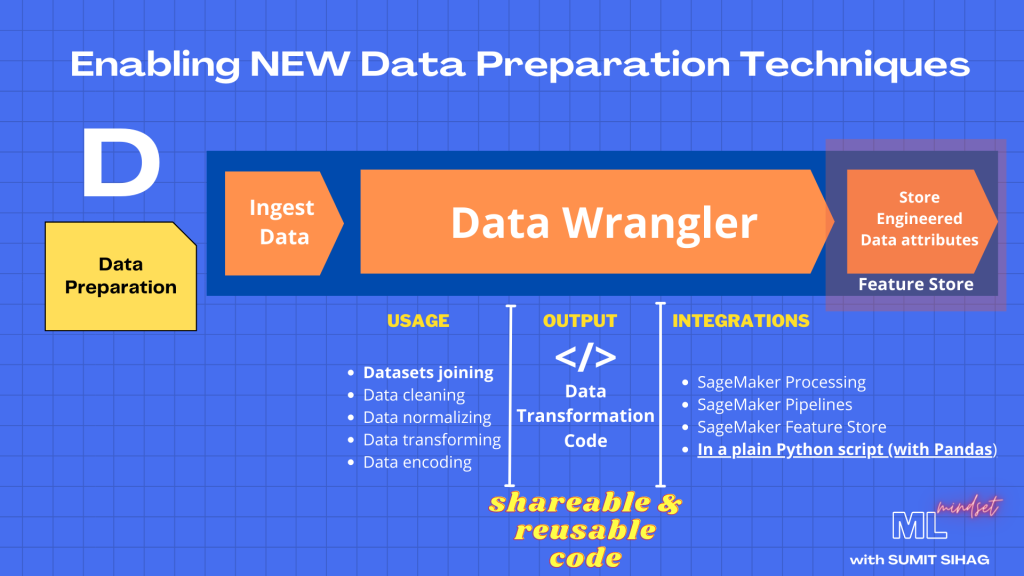
And that’s where AWS Data wrangler comes handy in reducing the communication cost between data engineers and data scientists. I think AWS Engineers have done a wonderful job in putting together the thought process and enabling new techniques of data preparation.
So by introducing this data wrangler toolset that produces a code which is reusable, executable and shareable , AWS has done a fantastic job to reinvent data preparation techniques. And literally gave a checkmate to its competitors.
That’s all for this blog. See you in the next episode on Feature Store.