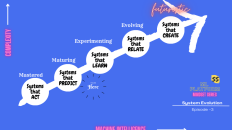
Writing to express my thoughts on the winning process in model development !
While leading model development following is the mental model that my engineering teams always adhere to:
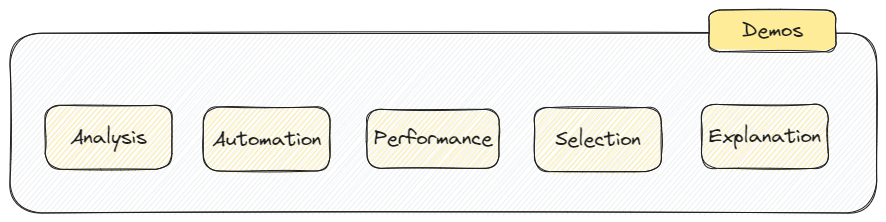
Today we will discuss some front runners (libraries and frameworks) that can help us to achieve this winning process.
Analysis
As we all know, data analysis (& data prep) is the backbone of any successful model development lifecycle. Three python libraries that are front runners and are extremely promising to perform data analysis:
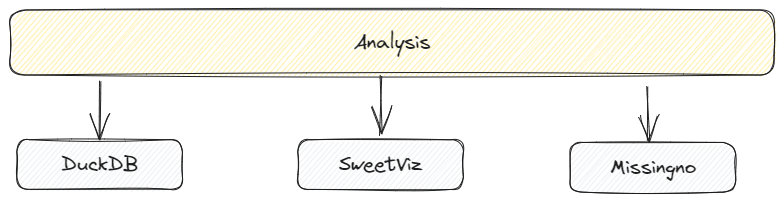
- DuckDB: an in-process, and serverless, sql OLAP optimized for interactive data analysis.
- SweetViz: an open-source python library to generate detailed data analysis, on source data, in a self-contained HTML.
- Missingno: a python based toolkit to Identify and Visualize missing data prior to feeding into model development pipeline.
Automation
Experimentation is very important in model development and at the same time it is equally important to fail fast and bring these experiments in production and that’s where automation comes handy to define the commercial success of these experiments. Three python libraries that can make experiments exponentially fast and efficient:
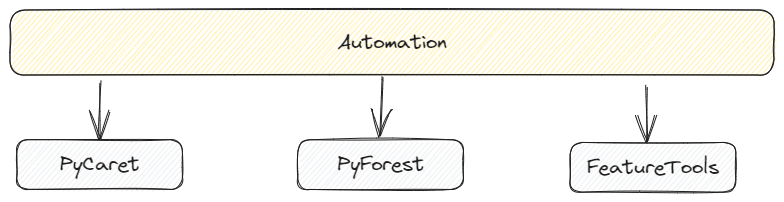
- PyCaret: a python wrapper around several ML libraries and frameworks such as scikit-learn, XGBoost, LightGBM, CatBoost and many more.
- PyForest: a lazy import of all the popular python data science libraries so that they are always there in your model development environment. Also a big challenge for enterprise compliance requirements.
- FeatureTools: based on “Deep Feature Synthesis” that stacks multiple transformation and aggregation operations to create features from data spread across many tables (or even multiple panda data frames).
Performance
With cloud and ‘one-click tooling’, we have the luxury to provision and scale infrastructure however are we utilizing the horse power of underlying infrastructure ? Two python libraries that can help us to maximize our utilization of our cores:
Modin: A python library that can handle data frames upto 1TB+ and can scale single threaded pandas to utilize all the cores of your underlying infra.
Parallel Pandas: A python library that takes care of splitting the original dataframe into chunks and parallelizing and aggregating the final result for us.
Explanation
Model Explainability is key and it is very important to understand model predictions to make decisions better for both social impacts as well as commercial success. Model explanation has to be performed in all the three stages of model development: Pre-modeling, Modeling and Post-Modeling.
Three libraries that can help us mature our model explainability :
- SHAP
- LIME
- XAI
All the above libs are model agnostic and helps in visualizing the predictions of machine learning models including feature importance scores.
Demos
‘Storytelling with Demos’ let us showcase a true value story. It is extremely important to demonstrate our model from development to prediction so that we can bring our experiments to production exponentially fast and efficient.
Two python frameworks that can help us to quickly assemble web apps to demonstrate functioning of our models:
- Streamlit
- Gradio
Streamlit is our favorite !
Thanks,
Sumit